Exploiting Multi-Modality Context for Enhanced Online Adaptive Pseudo-Labeling of Point Clouds
Master Thesis
Abstract
This thesis addresses the challenge of weakly supervised point cloud semantic segmentation by leveraging multi-modal information and introducing novel pseudo-labeling techniques. The objective is to reduce the laborious and time-consuming manual annotation process while maintaining competitive segmentation performance.
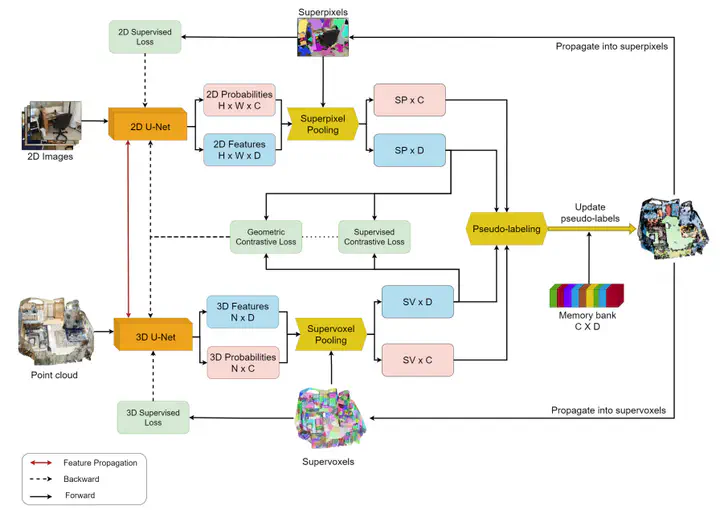
Existing state-of-the-art methods primarily focus on leveraging 3D modalities, such as point clouds and voxels, while disregarding the readily available 2D modality, including RGB images and depth maps. In contrast, this thesis proposes a comprehensive approach that integrates 2D RGB-D information into the pseudo-labeling and contrastive learning methods.
The proposed methodology exploits the geometric information derived from 2D-3D correspondences to establish consistency between the segmentation results of 2D and 3D modalities across the scene. To address the issue of sparse labels and enhance class representations, oversegmentation is employed to generate supervoxels and superpixels. The sparse labels are then propagated into the oversegmented regions, effectively increasing the label count. By matching supervoxel features with their corresponding superpixels in the embedding space, the proposed methodology enforces 2D-3D consistency throughout the scene. Furthermore, the sparse labels are leveraged to enforce consistency among supervoxels sharing the same label. Through the integration of 2D-3D consistency and contrastive learning, a robust online adaptive pseudo-labeling mechanism is introduced, eliminating the need for an additional network for pseudo-label generation.
Extensive experiments are conducted on popular datasets, including ScanNetv2 and 2D-3D-S, to validate the effectiveness of the proposed multi-modal integration, contrastive learning, and pseudo-labeling approaches. The experimental results demonstrate the superior performance and efficiency of the proposed methodology compared to existing methods, highlighting its potential for reducing manual annotation efforts and improving weakly supervised point cloud semantic segmentation.